JavaScript and DOM: Introduction
This page focuses on JavaScript and its implementation of Document Object Model (DOM). DOM is essentially an interface definition that provides a methodology to organize, traverse, search, and update HTML, XHTML, and XML documents. DOM treats a document as a hierarchical collection of various elements (referred to as a node); this document can be an HTML, XHTML, or XML page. As an example, these nodes could be the head element, the body element, a form element, a script element, and so on.
The DOM specification is provided by World Wide Web Consortium (W3C). W3C has released several versions of DOM specification; the current version is the Level 3 version and was published in 2004. We can find the DOM-related Technical Reports here: http://www.w3.org/DOM/DOMTR.
Document Object Model (DOM) provides specification for language-independent interface for managing HTML, XHTML, and XML elements. Since the specification is in terms of interface, it does not include implementation and leaves the implementation to vendors. Besides JavaScript, DOM implementation is also available for other programming languages likes Java, Python, PHP etc. Although DOM is applicable to HTML, XHTML, and XML documents, in this chapter, we focus on DOM's APIs for HTML documents.
For most part, JavaScript implementation provides DOM-related methods using the document object; document object is a property of the global window object. This chapter discusses methods provided by the document object that allow us to traverse, add, update, or delete elements of an HTML page.
One of the key advantages of DOM and JavaScript is that if needed, we can add, update, and delete elements of HTML pages dynamically -- as application logic varies during the course of user-interaction, we can use this powerful combination to re-render the HTML page in an asynchronous manner.
The DOM model uses a tree structure to represent elements of a page. The root of this tree is the document itself and its child elements (and the child elements of root's child elements) form the rest of the tree.
A tree structure allows us to navigate the tree easily. Each node can navigate to other nearby nodes depending upon the location of the nearby nodes with respect to the current node. A node that sits below a node is called a child node and DOM provides methods to reach to all child nodes from a parent node. On the other hand, a node that sits above the current node is a parent node and once again DOM provides methods to reach the parent node from the child nodes. Another relationship is that of sibling nodes -- sibling node sits at the same level (depth from the root of the tree) as the current node.
Let us use a simple example to understand the representation of an HTML page (provided below) using DOM. This page that has three elements in its body: a comment element, a paragraph element, and an ordered list element. We should note that DOM treats even comments as nodes.
<!doctype html>
<html>
<head></head>
<body>
<!-- A simple HTML page -->
<p> Wizard's To-Do list: </p>
<ol>
<li>Practice Spells</li>
<li>Visit Bilbo Baggins</li>
<li>Repair broken staff</li>
</ol>
</body>
</html>
Let us discuss the elements of the above HTML page. Being a tag-based language, HTML elements are identified using their tags. Thus, the above page consists of the following tags: the HTML page (identified by <html> tag), the head element (identified by <head> tag), the body element (identified by <body> element), a paragraph element (identified by <p> tag), an ordered list (identified by <ol> tag), a handful of list items of the ordered list (identified by <li> tag), and a comment element (identified as bounded between "").
All of the tags in this example are followed by a closing tag -- </head> for the head element, </p> for the paragraph element, </ol> for the ordered list element, </li> for the list entries, </body> for the body element, and "-->" for the comment element.
HTML offers a wide range of tags -- discussing them is beyond the scope of this article. We recommend the reader to refer to HTML specifications provided by W3C for additional reference (http://www.w3.org/html/).
We can use these HTML tags as a basis to build a DOM tree. Thus, the HTML page node has two child nodes: a head node and a body node. Since head node contains no elements, it has no have any child node. Next, the body node comprises of a comment node, a paragraph node, and an ordered list. The ordered list itself has three child nodes, each being an item of the list. Each of the comments, paragraph, and list item nodes also contain a child node that holds the text value of these elements. With this, the DOM tree would like as follows:
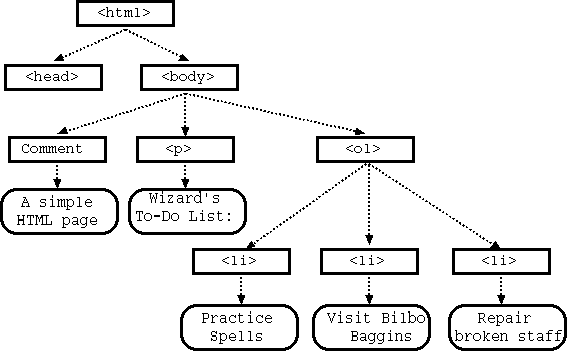
Figure: DOM Tree
Let us look at the above figure to provide examples of a child node, a parent node, and a sibling node. In the above figure, the <ol> node is a child node of the <body> element. The <html> node is the parent node of the <body> node. Lastly, the <head> node is a sibling node of the <body> node.
As we can see from the earlier example, a web documents (like an HTML page) can have elements (nodes) of varying types. DOM provides several types of nodes. In fact, DOM provides constants to reflect the type of nodes for various nodes. JavaScript defines these constants as properties of the document object. Hence, we can refer to them using document, e.g document.ELEMENT_NODE. These values are stored as the nodeType property of each element (more on this later). When needed, we can use the nodeType value to identify the type of of the node to perform node-specific tasks. Here are these constants:
| DOM Constant | Value |
|---|---|
| ELEMENT_NODE | 1 |
| ATTRIBUTE_NODE | 2 |
| TEXT_NODE | 3 |
| CDATA_SECTION_NODE | 4 |
| ENTITY_REFERENCE_NODE | 5 |
| ENTITY_NODE | 6 |
| PROCESSING_INSTRUCTION_NODE | 7 |
| COMMENT_NODE | 8 |
| DOCUMENT_NODE | 9 |
| DOCUMENT_TYPE_NODE | 10 |
| DOCUMENT_FRAGMENT_NODE | 11 |
| NOTATION_NODE | 12 |
Different types of DOM nodes have different characteristics, formally, identified as attributes. And thus, it is possible that given an attribute, two different types of nodes may not share it. As an example, an image element has an attribute of "src", but an ordered list does not have this attribute.
window.document Object
In JavaScript implementation of DOM, the main object that houses most of the DOM APIs is the document object; the document object is itself derived from the window object. In this section, let us learn a little bit more about the document object! In fact, we have already seen one of the key methods of document object: document.getElementById(); this method allows us to get an element of the HTML page using an ID.
The document object contains a large number of properties. These properties allow document object to provide several functionalities. The first set of document properties allow us to get a handle of HTML elements (like getElementById(), getElementsByTagName, getElementsByName() etc). The second set of document properties allow us to create, add, delete, and replace HTML elements (like createElement(), appendChild(), removeChild(), replaceChild() etc). The third set of document properties allow us to traverse the DOM tree (with properties like childNodes, parentNode, nextSibling, previousSibling etc). In addition, the document also provides a large number of properties for managing document events (like onclick, onsubmit, onfocus etc); more on event handlers a little later.
To see all the properties provided by the document object, we can use a simple for/in loop to iterate over its properties. Here is the example:
<!doctype html>
<html>
<div id="div_id"> </div>
<script type="text/javascript">
// Get a handle for the div element.
var elem = document.getElementById('div_id');
// Print properties of the document object
for (item in window.document) {
elem.innerHTML += item + ", ";
}
</script>
</html>
Note that due to browser incompatibilities, we might find that the output of the above example could be different for different browsers.