Linked List: Doubly Linked Lists
With a doubly linked list, each node has two pointers: (a) a "next" pointer that connects it with the next node in the list and (b) a "prev" pointer that connects it with the previous node in the list. A doubly linked list also has two main pointers, a head and a tail. The head points to the first node of the list and the tail points to the last node of the list. We interchangeably refer to an element of a linked list as a node.
The following figure illustrates the usefulness of the next and prev pointers; the next pointer allows us to navigate from the head to the tail. The prev pointer allows us to navigate from the tail to the head. Together, they provide a bi-directional traversal. For the tail node, the next field points to a NULL since there is no node after that. Likewise, for the head node, the prev field points to a NULL since there is no node before that.
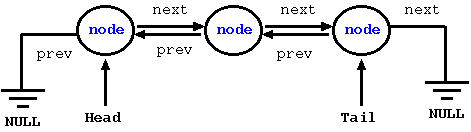
Figure: A Doubly Linked List
Each element of a doubly linked list is represented by a data structure. As per the above figure, the structure contains both next and prev pointers. The structure also has a member "value" that stores integer values -- the basic reason why we need a linked list!
typedef struct doublylinkedlist_node {
struct doublylinkedlist_node *next;
struct doublylinkedlist_node *prev;
int value;
} doublylinkedlist_node_t;
Note that the compiler would not complain that we define both the next and prev as pointers to the struct doublylinkedlist_node. This works because the storage of a pointer is fixed and the compiler allocates that much storage for it. However, if we were to keep the full structure as variable inside the structure (e.g. "struct doublylinkedlist_node next" followed by "struct doublylinkedlist_node prev"), then the compiler would not like it and complain that the next and the prev fields are incomplete types!
Basic Operations
Doubly Linked lists allow us to store data on a dynamic basis and do useful things with it. For that purpose, doubly linked lists support a range of useful operations; these operations are similar to that of a singly linked list. Some of these operations are traversing elements of the list, inserting nodes into the list, searching for a given element in the list, and deleting an existing element from the list.
Traversing the list
Traversing a linked list is a fairly straightforward task. We can traverse a doubly linked list in two ways. First, we can start at the head node and then traverse the nodes in the forward direction. Alternatively, we can start at the tail and then traverse the nodes in the reverse direction. Most of the linked list operations do involve traversal. For example, if we are searching for a specific node, then we need to traverse the list, till we find the node that we are looking for. Same logic applies when we are trying to delete a specific node.
Searching a node
Searching a node is a good example of node traversal in a linked list. The steps involve a while loop to walk the linked list, starting from the head (or the tail). As we do the walk, we compare each node with the passed value.
One side note. Since lookups involve traversal, their time complexity becomes O(n). So, if your system spends most of its time in lookup operations and if you dealing with a large number of elements, then you should also consider alternative data-structures like a hash table or a balanced binary tree. A hash-table usually takes O(1) average time for a lookup, but the worst-case time-complexity is same as that of arrays (O(n). A balanced binary tree takes O(logn) for a lookup.
Inserting a node
Inserting a node in a list is simply a matter of allocating the new node and adding it at the end of the tail. To do that, we need to manipulate a handful of pointers. This involves updating the pointers (both next and previous) of neighboring nodes such that the new node becomes a new link in the list. Of course, there is one corner case. When we add a node, and if it is the first node of the list, then we should make both head and tail of the list point to this new node.
We illustrate inserting a node for a doubly linked list using the figure provided below. The following figure shows a list consisting of four nodes with values of 680, 880, and 280. Next, we add a new element with value 780.
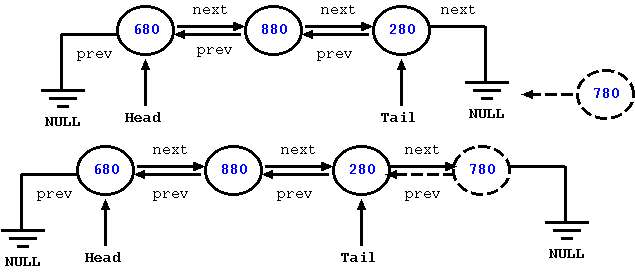
Figure: Inserting into a Doubly Linked List
Deleting an element
Like insertion, when we delete a node, then we need to update both next and prev pointers of the neighboring nodes of the node being deleted. With deletion, we should also free the memory allocated for the node.
The following figure illustrates deletion of the node with value 880. For this, we simply make the next pointer of the node before 880 (which has value 680), point to the node after 880 (which has value 280). In addition, we make the prev pointer of the node with value 280, point to of the node with value 680.
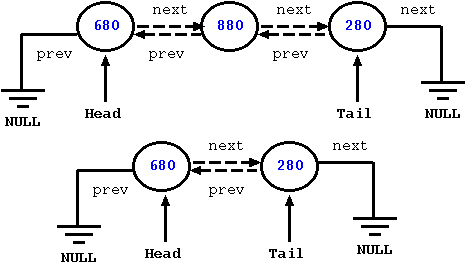
Figure: Deleting a node from a Doubly Linked List
When deleting, we have to take into account that if the node being deleted is the head/tail itself; if so, then it updates the doublylinkedlist_head/doublylinkedlist_tail accordingly.
Implementation
Let us now get cracking and implement various operations for a doubly linked list. The implementation consists of various C functions that provide each of the above operations. These functions help us add a new element in the linked list (doublylinkedlist_insert()), delete an element from the linked list (doublylinkedlist_delete()), search an element in the the linked list (doublylinkedlist_search()), and free the entire linked list (doublylinkedlist_free()). In the end, we put all the functions together using the main() function.
And here is the implementation of the main function. The file contains both data-structures and functions.
#include <stdio.h>
#include <stdlib.h>
typedef struct doublylinkedlist_node {
struct doublylinkedlist_node *next;
struct doublylinkedlist_node *prev;
int value;
} doublylinkedlist_node_t;
/* This is the head of the doubly-linked list */
doublylinkedlist_node_t *doublylinkedlist_head = NULL;
/* This is the tail of the doubly-linked list */
doublylinkedlist_node_t *doublylinkedlist_tail = NULL;
void doublylinkedlist_print () {
doublylinkedlist_node_t *node = doublylinkedlist_head;
printf("Linked List (from head): ");
for (node = doublylinkedlist_head; node != NULL; node = node->next) {
printf("%d ", node->value);
}
printf("\n");
printf("Linked List (from tail): ");
for (node = doublylinkedlist_tail; node != NULL; node = node->prev) {
printf("%d ", node->value);
}
printf("\n");
}
doublylinkedlist_node_t *doublylinkedlist_search (int search_value) {
doublylinkedlist_node_t *node = NULL;
for (node = doublylinkedlist_head; node != NULL; node = node->next) {
if (node->value == search_value) {
return node;
}
}
return NULL;
}
void doublylinkedlist_insert (int value) {
doublylinkedlist_node_t *node, *next, *new_node;
new_node = (doublylinkedlist_node_t *)malloc(sizeof(doublylinkedlist_node_t));
if (new_node == NULL) {
printf("Malloc Failure\n");
return;
}
new_node->value = value;
new_node->next = new_node->prev = NULL;
if (doublylinkedlist_head == NULL) {
/* new_node is the head and tail */
doublylinkedlist_head = new_node;
doublylinkedlist_tail = new_node;
return;
}
/* Make the next of the current tail point to the new node */
doublylinkedlist_tail->next = new_node;
/* Make the previous of the new node point to the current tail */
new_node->prev = doublylinkedlist_tail;
/* Make the new node, the new tail */
doublylinkedlist_tail = new_node;
}
void doublylinkedlist_delete (int value) {
doublylinkedlist_node_t *node = doublylinkedlist_head;
doublylinkedlist_node_t *prev = doublylinkedlist_head;
doublylinkedlist_node_t *next, *node_to_free = NULL;
while (node) {
if (node->value == value) {
node_to_free = node;
next = node->next;
if (node == doublylinkedlist_head) {
prev = doublylinkedlist_head = node->next;
prev->prev = NULL;
} else if (node == doublylinkedlist_tail) {
doublylinkedlist_tail = node->prev;
prev->next = NULL;
} else {
prev->next = node->next;
next->prev = prev;
}
node = node->next;
printf("Deleted: %d\n", node_to_free->value);
free(node_to_free);
/* There may be more nodes with the same value, so continue. */
continue;
}
prev = node;
node = node->next;
}
}
void doublylinkedlist_free () {
doublylinkedlist_node_t *node, *prev_node;
if (!doublylinkedlist_head) {
return;
}
node = doublylinkedlist_head;
while (node) {
prev_node = node;
node = node->next;
free(prev_node);
}
doublylinkedlist_head = doublylinkedlist_tail = NULL;
return;
}
int main (int argc, char *argv[]) {
doublylinkedlist_node_t *node, *ret_node, *prev_node;
int input_array[] = {680, 880, 280, 780, 980};
int len = sizeof(input_array)/sizeof(input_array[0]);
int val_to_search, random_counter, i;
doublylinkedlist_head = doublylinkedlist_tail = NULL;
for (i = 0; i < len; i++) {
doublylinkedlist_insert(input_array[i]);
}
doublylinkedlist_print();
random_counter = random() % len;
val_to_search = input_array[random_counter];
ret_node = doublylinkedlist_search(val_to_search);
if (ret_node == NULL) {
printf("Not Found: %d\n", val_to_search);
} else {
printf("Found: %d\n", val_to_search);
}
random_counter = random() % len;
printf("Let us delete the value (%d) from the linkedlist\n",
input_array[random_counter]);
doublylinkedlist_delete(input_array[random_counter]);
doublylinkedlist_print();
/* All done! Free the doubly-linkedlist */
doublylinkedlist_free();
return 0;
}
The above implementation starts with definition of the doublylinkedlist_node_t that represents each node in the doubly linked list. As illustrated earlier, the structure has both next and prev pointers. Next, the above file defines two global pointers, doublylinkedlist_head and doublylinkedlist_tail; these two represent the head and the tail of the list, respectively.
The implementation has various functions that focus on each tasks. The doublylinkedlist_print() illustrates a simple traversal and as we visit each node, we print its value. Along the similar lines, doublylinkedlist_search() also walks through each node and compares the value of the current node with the passed value -- the moment it finds the node with a value that matches the passed value, it returns. The doublylinkedlist_insert() adds the node straightaway to the tail of the list -- pretty simple! Lastly, doublylinkedlist_delete() also does a walk, searching for the element that needs to be deleted. When it finds a node with that value, then it deletes that node. The deletion means that the next pointer of the previous node points to the next node of the current node. In addition, it also makes the previous pointer of the next node point to the previous node of the current node.
Note that the above code includes "stdlib.h" header file for the malloc() call; this include file is a standard C header that contains declaration for functions like malloc(), calloc(), free() etc. On some systems, you might find "malloc.h" as well that will contain these definitions -- but, we should refrain from including "malloc.h" since it is not standard and may not be available on all systems; we recommend doing a "man stdlib.h" for more details.
In the end, the main function calls these functions to do insert, print, search, and delete operations. Here is the output.
user@codingbison $ gcc doublylinkedlist.c -o doublylinkedlist user@codingbison $ ./doublylinkedlist Linked List (from head): 680 880 280 780 980 Linked List (from tail): 980 780 280 880 680 Found: 780 Let us delete the value (880) from the linkedlist Deleted: 880 Linked List (from head): 680 280 780 980 Linked List (from tail): 980 780 280 680 user@codingbison $
Advanced Implementation
With the above implementation, we store integer values in nodes of the list. However, if you are building a generic doubly linkedlist that can be used for various types of data-types, this may not be enough. So, for those use-cases, we would need to modify the earlier program so that it can now store data of any type.
Equally important, the above implementation is a monolithic program, where all the definitions and the main() function reside in the same file. When dealing with industrial-strength software, this would not be the case. Accordingly, we would have to split the earlier implementation into three files: (a) a header file that publishes the data-structure and APIs, (b) a C file that has the implementation of all the APIs that are published in the above header file, and (c) another C file that contains the main() function, which calls various linkedlist APIs.
Lastly, for simplicity sake, we are using a global head (doublylinkedlist_head) and tail (doublylinkedlist_tail) in the program. Using global variables, like this is also a No-No. If we are to use the same implementation for various clients, then we would have to rewrite this part, so that each client can have their own head and tail, without interfering with each other.
So, with our generic implementation, we are going to provide these three files one by one. Let us start with the header file (we call it "doublylinkedlist.h"). This file (provided below) starts by rewriting the earlier doublylinkedlist_node_t structure and makes the "value" now a "void *" instead of an "int". Next, it adds a new structure (doublylinkedlist_t) that is used for encapsulating the head and the tail pointers. In addition, the structure also adds a comparison callback function. We need applications to provide this function since applications can provide their own data type and the core implementation does not get to see what is inside the "void *". Therefore, the implementation really does not know how to compare two values. Keeping this with the application allows us to provide a more flexible implementation.
If you would like to see an implementation that follows the above suggestions, then you can view the complete program here: Advanced Implementation of Doubly Linked Lists.