HTML DOM
DOM (Document Object Model) provides an interface definition for searching, traversing, and updating HTML documents. The DOM specification is provided by World Wide Web Consortium (W3C). W3C has released several versions of DOM specification; the current version is the Level 3 version and was published in 2004. We can find the DOM-related Technical Reports here: http://www.w3.org/DOM/DOMTR.
DOM treats a document as a tree-based hierarchical collection of elements (also referred to as nodes). The root of this tree is the document itself and its child elements (and the child elements of root's child elements and so on) form the rest of the tree. These nodes could be the head element, the body element, a form element, a script element, a comment element, etc.
An HTML page can have elements (nodes) of varying types and DOM provides different types for different elements.
A tree structure allows us to navigate the DOM easily. Each node can navigate to other nearby nodes depending upon the relative location of the nearby nodes. A node that sits below a node is called a child node. On the other hand, a node that sits above the current node is called a parent node. Another interesting relationship is that of sibling nodes -- a sibling node sits at the same level (depth from the root of the tree) as the current node. DOM provides methods to navigate to all of these types of nodes and many more!
Let us use a simple example (given below) to understand the representation of an HTML page using DOM.
<!doctype html>
<html>
<head>
<title>Learning HTML DOM</title>
</head>
<body>
<p> Elements of Sun are: </p>
<ol>
<li>Hydrogen </li>
<li>Helium </li>
<li>Oxygen </li>
<li>Carbon </li>
<li>Neon </li>
<li>Iron </li>
</ol>
</body>
</html>
Let us discuss various elements that are present in the above HTML page. Since HTML elements are identified using their tags, we can see that the page has several elements: the HTML element itself (identified by <html> tag), the head element (identified by <head> tag), the title element (identified by the <title> tag), the body element (identified by <body> element), a paragraph element (identified by <p> tag), an ordered list (identified by <ol> tag), and a handful of list items of the ordered list (identified by <li> tag).
So, how exactly does the DOM tree look like?
The good news is that we can use these HTML tags as a basis to build it and see for ourselves! Thus, the HTML page node has two child nodes: a head node and a body node. The head node has title node as its child element. The body node comprises of a paragraph node, and an ordered list. The ordered list itself has three child nodes, each being an item of the list. Each of the paragraph and list item nodes also contain a child node that holds the text value of these elements. With this, here is how the DOM tree would like:
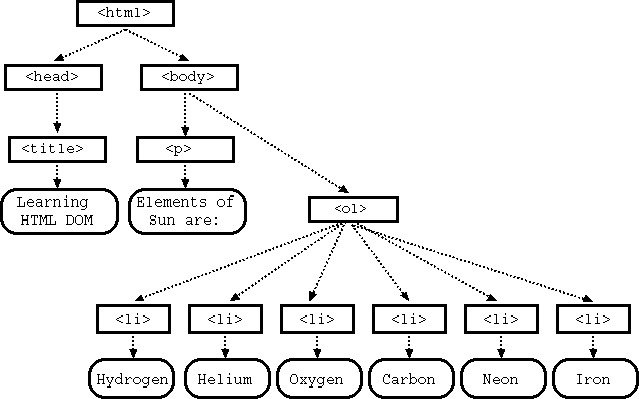
Figure: DOM Tree
Let us use the above figure to see example of various relationships between the nodes. The <ol> node is a child node of the <body> element. The <html> node is the parent node of the <body> node. The <head> node is a sibling node of the <body> node.
Document Object Model (DOM) provides specification for language-independent interface for managing HTML elements. Since the specification is in terms of interface, it does not include implementation and leaves the implementation to vendors. Besides JavaScript, DOM implementation is also available for other programming languages likes Java, Python, PHP etc.