HTML Basics: Overview
HTML stands for Hyper Text Markup Language. It is used by Internet browsers to display web content in a structured manner. In this module, we focus on HTML4 (HTML 4.01) version of HTML. We would touch upon HTML5 as and when needed. HTML is a tag-based language and uses tags to identify its elements. Authoring an HTML document is simply a matter of putting content within the relevant tags. For example, if we have to create a paragraph for some text, we can use the <p> tag to mark the start of the paragraph add the text, and then use the </p> to end the paragraph. In fact, the entire HTML document itself sits within two tags -- it begins with <html> tag and once the entire document is done, it ends with the </html> tag.
Like the above examples of <p> and <html>, majority of HTML elements are identified as a pair of tags: the first tag (the opening tag) marks the beginning of an element and the second tag (the closing tag) marks the ends of that element. However, there are a handful of HTML elements that work just fine even with one single tag. These elements do not enclose any content and hence, all they need is the opening tag. Since they do not enclose any content, they are also known as empty elements, void elements, or singleton elements.
In terms of structure, an HTML document has two prominent tags: head and body. The head section is identified by the <head> and </head> tag-pair and contains meta-information of the HTML page (like say, the title of the page). The body section is identified by the <body> and </body> tag-pair and encloses the actual content of the HTML page. However, these head and body tags are optional. Thus, it is possible to have a valid HTML page that does not contain any these four tags: <head>, </head>, <body>, and </body>!
HTML also provides elements and attributes that focus on accessibility. These constructs help us render content for non-visual readers like non-graphic display terminals, speech synthesizers etc. As we go along, we would make a note as and when we touch upon these elements. When we write an HTML document, it is important that we pay attention to these elements since they would make the document more widely acceptable.
How does HTML work?
So, how does all of this work? We start by keeping the HTML page (file) on the web server sitting somewhere in the Internet. Under the covers, when a user enters a URL in the browser, then the browser sends a request to the web server and asks for the page typed in the URL. Next, the server responds to this request by sending the requested page. Once the browser gets the page from the server, it would go ahead and render it. Here is a simple illustration for this request-response flow.
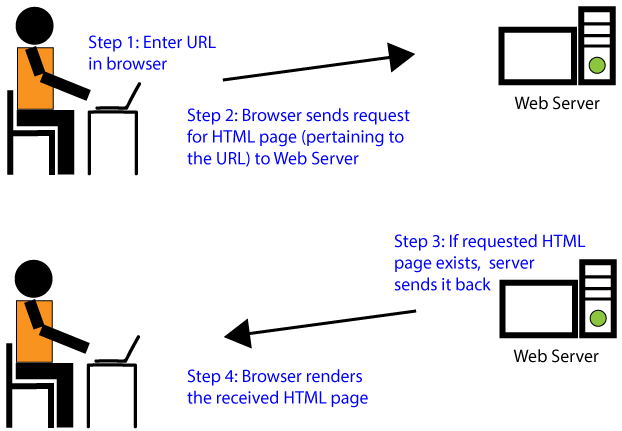
Figure: Browser Talks to Server
You might be wondering what does the server do if we request for a page that it does not have. Well, even in that case, the server sends a respond back to the browser but it sends with a special error value (404 error value) to indicate that it does not have the requested page.
Example: Hello World
Now that we are familiar with a little bit of HTML basics, let us dive into it and write our very first HTML document! We provide the document below.
<!doctype html>
<html>
<head>
<title> Hello World! </title>
</head>
<body>
<!-- This is a comment -->
Hello World!
</body>
</html>
Let us now describe various elements in the above example.
The example begins with the doctype declaration -- this should be the first thing in an HTML document. The doctype declaration is used to indicate the markup language and the version of the page to the Internet browsers. Without this declaration, some of the browsers could use their own default mode. One such default mode is the quirks mode. Unfortunately, the quirks mode is not standard across various browsers. As such, trying to ensure that an HTML page works consistently in all browsers would become a nightmare of Orwellian proportions! To help us not do this mistake, the W3C specification makes it an error to not declare the doctype for a document. If you still decide to skip the doctype, well, you have been warned!
Now, a moment of truth! Strictly speaking, the "<!doctype html>" is used for HTML5 documents. However, as per W3C, we should use it even if do not plan of using any of the new HTML5 features on the page. This doctype still validates most of the HTML 4 features and as such, there is no disadvantage to using this doctype. For more on doctypes, please visit the W3C page: http://www.w3.org/wiki/Doctypes_and_markup_styles.
After the doctype declaration, the example has the html element that starts with the <html> tag ) and its in the end, closes with the </html> tag. Thus, with the exception of the doctype, the rest of the page content sits inside the html element. Next, the html element itself contains two child elements: head and body. The head element (identified by <head> and </head>) does not contain much except the title element. We should mention that as per W3C, it is mandatory to have a title element for each HTML page. Next, the body element (identified by <body> and </body>) has two child elements of its own: a comment element and a text.
Let us load this page in a browser. To do that, we would need to enter the location of the file (in this case, "localhost/hello.html") in the browser address field. Once loaded, we would notice two things. First, the browser displays the "Hello World!" in the main window - this is the text present in the body element. Second, we would also see the browser displaying "Hello World!" along with "Mozilla Firefox" in the title bar -- this is the text added in the title element (we use Mozilla Firefox for our example). In case you are wondering, it is common for browsers to append the HTML title with their name.
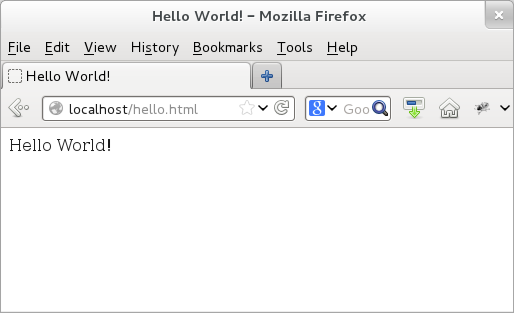
Figure: Hello World